
Production RAG in minutes
Skip the complex infrastructure setup and boilerplate code. We handle ingestion, embedding, and scaling so you can focus on building your product.

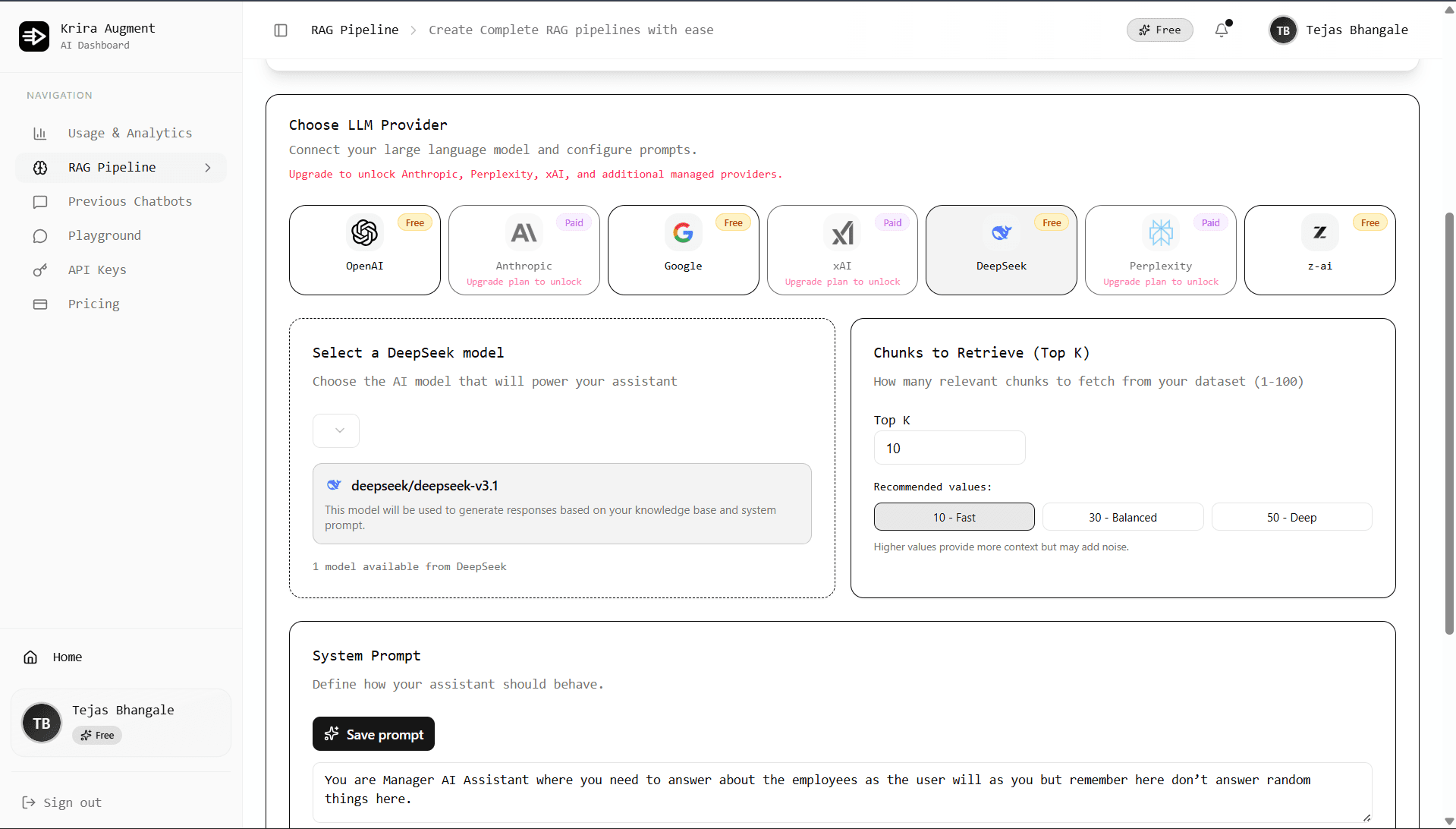
Skip the complex infrastructure setup and boilerplate code. We handle ingestion, embedding, and scaling so you can focus on building your product.
Everything you need to build, scale, and optimize your production RAG pipelines with precision.
Advanced splitting strategies with automated data cleaning to preserve meaningful context at scale.
Lightning-fast vector generation with native GPU support for high-throughput embedding processing.
State-of-the-art retrieval algorithms optimized for semantic accuracy, speed, and relevance ranking.
Connect seamlessly with popular platforms and services to enhance your RAG workflow.

Scalable and managed vector database for high-throughput applications.

Open-source AI application database for building LLM apps.

The AI community building the future. Hub of models and datasets.
Advanced open-source LLMs with coding capabilities.

Frontier models including GPT-4o for complex reasoning.
AI research and products that put safety at the frontier.
Multimodal AI models from Google DeepMind.
Open bilingual language models optimized for performance.
Real-time search and answer engine powered by LLMs.
End-to-end RAG infrastructure scaling to millions of documents.
Transparent pricing for every stage of your growth. Start free and scale as you need.
Includes
Includes
Includes
Have more questions? Reach out to our support team.